Yair Lifshitz
May 30th, 2023
In the early days of the 20th century, I was a young software engineer at Intel Corp. Hosted services as we know them did not yet exist; much of my understanding of how to debug large systems did not yet materialize; and I still had a full set of hair.
Our team developed a Static Timing Analysis tool; this is a CAD tool that is used for designing huge chips, and often take hours to run. Sometimes our tool would appear to be stuck for hours, or progress very slowly. Debugging these cases would typically involve turning on logging, and digging through (what back then appeared to be) tons of text.
One day, someone in the team had an idea: we’ll collect real-time statistics; post them in a shared memory location; and write a GUI so these statistics can be viewed and analyzed in real time. This turned out to be gold mine: simply by seeing how fast a specific counter is progressing I could often guess what the underlying issue is in a minute, saving tons of reproduction and debug efforts.
When we started shipping Robot 1-X, one thing that immediately came up was how brittle LLMs are; a prompt that works great with one input, would fail horrible on a slightly different input; the same prompt called repeatedly would fail sporadically for any temperature other than 0; and our ability to generate good test coverage was slim to nonexistent.
One thing we found extremely useful is real-time statistics collection. Call it insights, telemetry, or any other name – the more unknowns you have, the more value you get from collecting statistics about your code’s behavior at runtime.
With LLMs, there are lots of unknowns.
Case 1: plug-in support with GPT 3.5
Robot 1-X has a homemade plug-in system, supporting Google Search, and Weather lookup. This works exceptionally well with GPT-4 from a correctness standpoint; but is extremely slow and expensive.
To enable plug-in support for all users, we did multiple iterations of prompt tweaking, to make this workable with GPT 3.5; the code has a backup path in case the main plug-in flow fails, providing the user with a “dumb” answer.
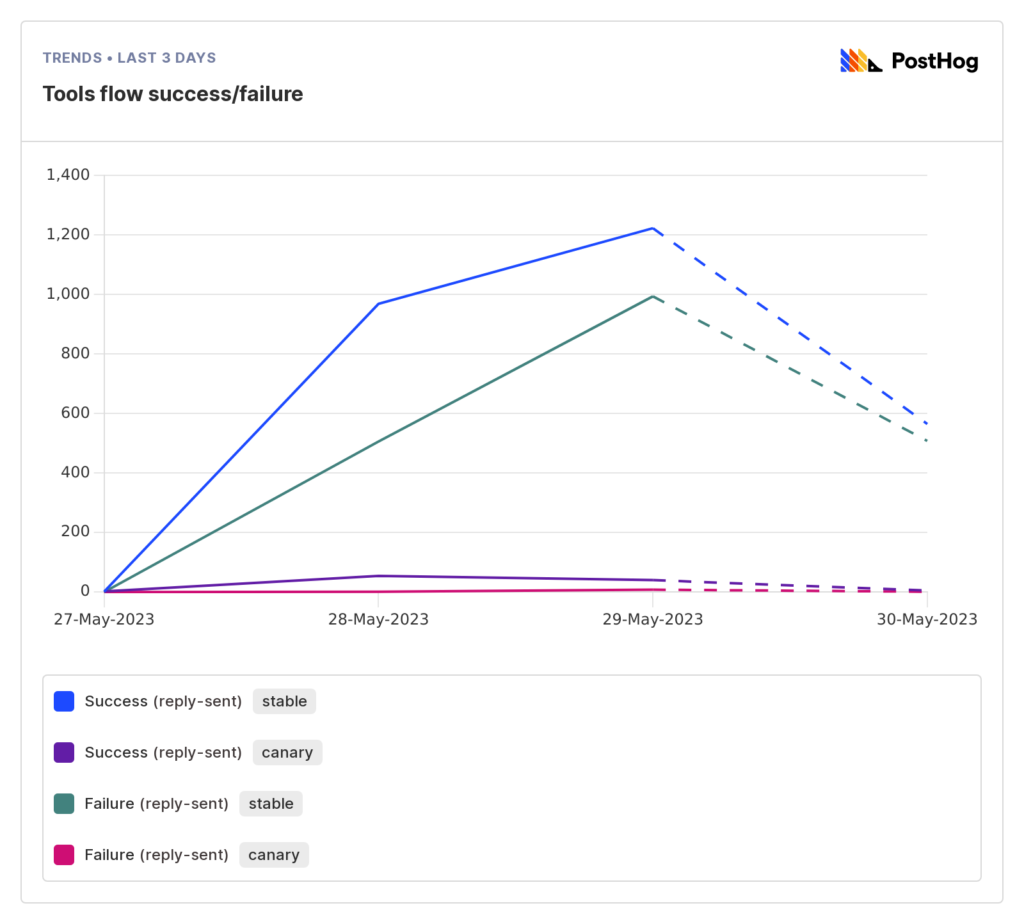
While all our initial tests appeared to work correctly, monitoring the actual numbers shows that success rates for the “Tools” flow for GPT-3.5 (our “stable” branch) are ~60%; this means 40% of user queries fall back to the “dumb” flow. This was disparaging compared to our >95% success rate in manual testing, and some debug allowed us to define a much better implementation – more on that (hopefully) in a separate post soon.
It’s a bit hard to see below, but our GPT-4 implementation (“canary” branch) fares very well, with a >90% success rate.
Case 2: content filtering
We recently moved our GPT-3.5 provider from OpenAI to Azure, getting a significant performance boost. We were very happy with the results, and quickly pushed the new integration to production.
What we did NOT expect is Azure’s content filtering blocking some replies, leaving us hanging with nothing to show the user. This was exacerbated by the fact that once a user makes a sexually explicit comment, and offensive remark, or references an illegal activity, this message remains in the chat history windows for a few extra messages, effectively triggering content filtering for each and every new message.
OpenAI’s GPT implementation also does not answer such requests; however, it does so in a more graceful way, providing a well-phrased answer for the user. As a quick fix, we implemented a fallback mechanism which invokes OpenAI’s GPT-3.5 implementation whenever Azure filters our content; not perfect, but how well this works depends on how often content gets filtered.
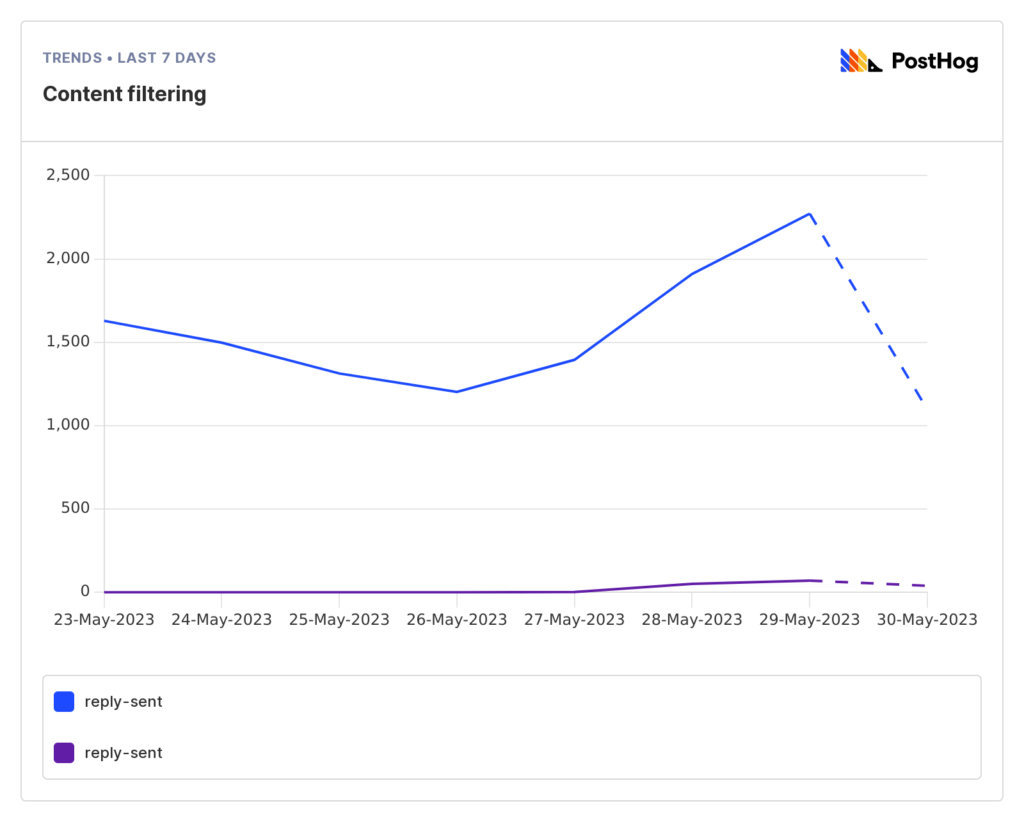
Measurements have shown us ~3% of our API calls get filtered, maxing at 5% daily. Definitely something to work on, but not a showstopper that should cause an all-stop on other fronts.
Summary
LLMs are a new technology, and as such, are not yet mature. Their indeterministic and sometimes inexplainable nature makes it harder to integrate them into products.
Collecting data about each LLM invocation and its implications allows making engineering calls around a component that is, as of now, still unpredictable.
More on how we solved our main GPT-3.5 problems in our next post.
Leave a Reply